Видео с ютуба Llm Inference

Почему делать логические выводы сложно...

AI Inference: The Secret to AI's Superpowers

Освоение оптимизации вывода LLM: от теории до экономически эффективного внедрения: Марк Мойу

Deep Dive: Optimizing LLM inference

Understanding the LLM Inference Workload - Mark Moyou, NVIDIA

Deep Dive into LLMs like ChatGPT

What Is Llama.cpp? The LLM Inference Engine for Local AI

Stanford CS336 Language Modeling from Scratch | Spring 2025 | Lecture 10: Inference

Large Language Models explained briefly

CMU LLM Inference (1): Introduction to Language Models and Inference

Невероятно быстрый вывод LLM с этим стеком

Faster LLMs: Accelerate Inference with Speculative Decoding

Understanding LLM Inference | NVIDIA Experts Deconstruct How AI Works

How the VLLM inference engine works?

What is vLLM? Efficient AI Inference for Large Language Models
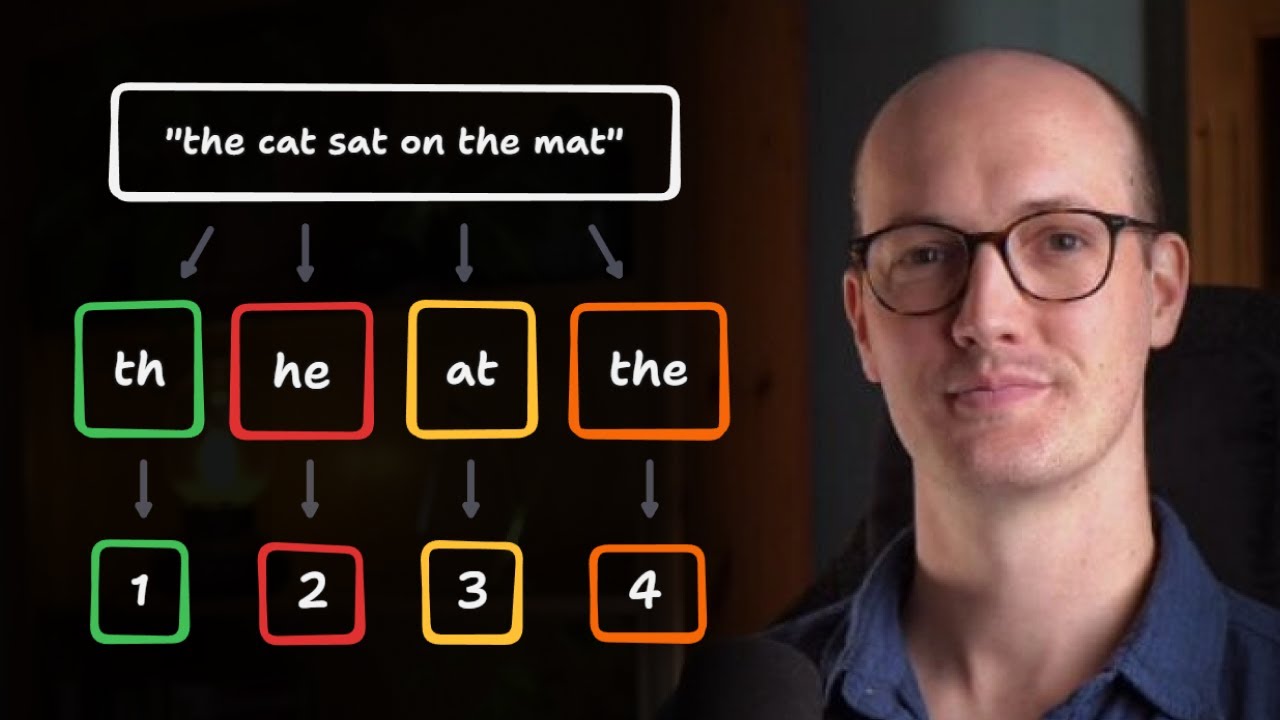
Большинство разработчиков не понимают, как работают токены LLM.

Large Scale Distributed LLM Inference with LLM D and Kubernetes by Abdel Sghiouar

High Performance LLM Inference in Production
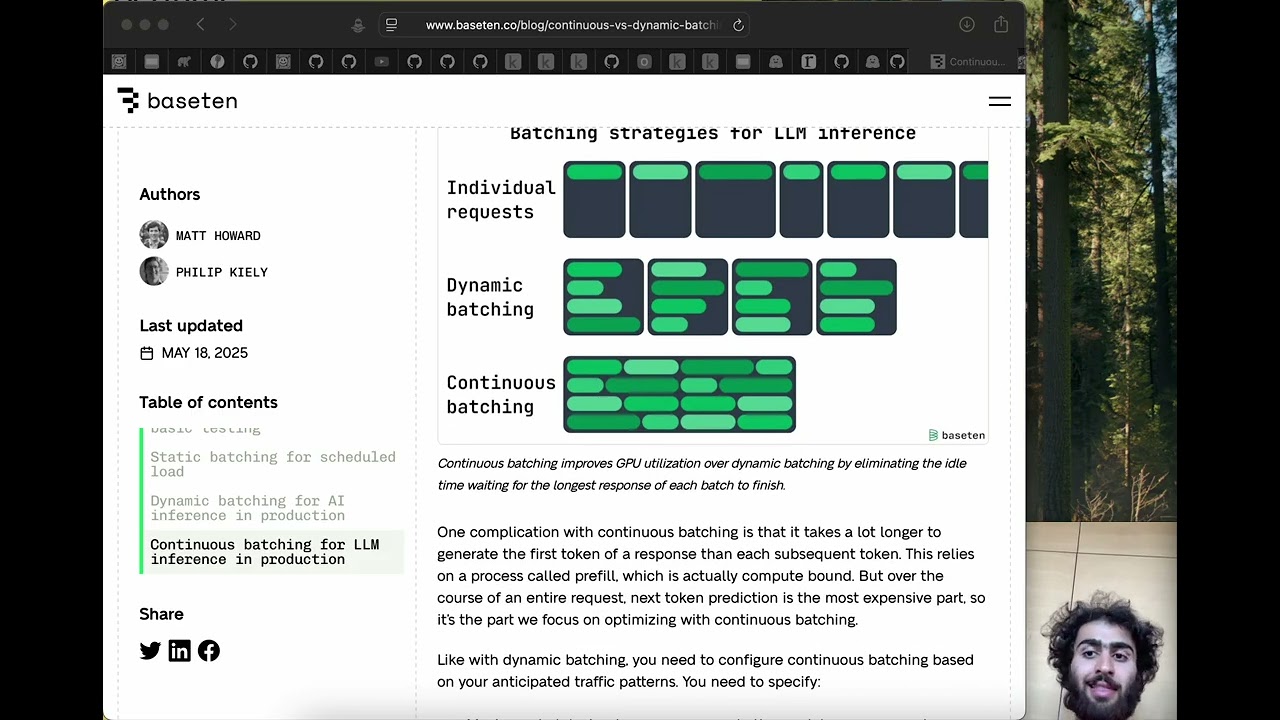
Gentle Introduction to Static, Dynamic, and Continuous Batching for LLM Inference

Inference at Scale: The New Frontier for AI Infrastructure and ROI